Stochastic Gradient Descent explained in real life
Predicting your pizza’s cooking time

Gradient Descent is one of the most popular methods to pick the model that best fits the training data. Typically, that’s the model that minimizes the loss function, for example, minimizing the Residual Sum of Squares in Linear Regression.
Stochastic Gradient Descent is a stochastic, as in probabilistic, spin on Gradient Descent. It improves on the limitations of Gradient Descent and performs much better in large-scale datasets. That’s why it is widely used as the optimization algorithm in large-scale, online machine learning methods like Deep Learning.
But to get a better understanding about Stochastic Gradient Descent, you need to start with Gradient Descent part of it.
Cauchy’s Legacy: Gradient Descent
The history of Gradient Descent and optimization algorithms didn’t start with modern Machine Learning, it goes all the way back to 19th century France.
The French Mathematician, Engineer and Physicist Augustin Cauchy pioneered the fields of complex analysis and abstract algebra. And his influence is forever imprinted in Mathematics and Physics, with the several theorems and concepts that are named after him, like the Cauchy Distribution, Cauchy Theorem or Cauchy Elastic materials.

Among Cauchy’s many pivotal contributions, he’s also said to have developed Gradient Descent.
Cauchy’s motivation was that he wanted to compute the orbit of an heavenly body without solving differential equations, solving instead the algebraic equations representing the motion of said body[1].
Gradient Descent, the steepest descent
Gradient Descent is also called steepest descent. The idea behind the algorithm is to find an efficient way of reaching the minimum value of a function.
This is exactly what you want to do in a Machine Learning model!
The model’s loss function, usually referred to as cost function, tells you how good the model is fitting the training data. The more you minimize the cost function, the better the model fit.
What’s particular about gradient descent is that, to find the minimum of a function, the function itself needs to be a differentiable convex function. These names sound complicated, but there’s an intuition to it.

Convex function
When you hear convex function, visualize a function that’s shaped like a bowl.
The simplest convex function is the parabola.

Differentiable function
A differentiable function is any given function that has a derivative for each of its point.
The derivative of a function at x is the slope of the graph of the function at point (x, f(x)).
Let’s unpack the concept of derivative.
The slope of a linear function is the rate at which it rises or falls, you can think of it has describing the direction of that function. But this intuition only works for linear functions.
For non-linear functions, the slope can be different at different points. To find the slope of a non-linear function at a specific point p, you need to find the slope of the tangent at point p.
The tangent line of a function at point p is the line that best approximates the function in that point.
The tangent is an approximation so, finding the slope tangent at a specific point, is like eyeballing the slope of the function at that point[2].

To add more precision to the slope of a tangent, you need to find the slope of the secant line at point p.
The secant line is a more precise way of approximating tangent lines.
The secant is still an approximation, but it has more precision because it uses two points, the tangency point and a second point.

As the second point chosen gets closer to the point of tangency, the better the approximation will be.
So, to find the exact slope of function f at the point of tangency p = (x, f(x)) you find the secant when the limit of the change in x tends to zero.

If the limit exists, that’s the derivative of the function f at point (x, f(x)).

But you might be wondering, what does all of this have to do with Gradient Descent?
What is a gradient anyway?
The gradient of a function is the collection of all its partial derivatives organized into a vector[3], and is represented by an inverted triangle, called the nabla.
In a machine learning model, you can think of the gradient as the collection of partial derivatives, each one with respect to one of the model’s features.

The gradient of a function will always point in the direction where there’s the greatest increase in the function. If your function were a mountain, the gradient always wants to reach the summit.
To see how the gradient always goes in the direction of greatest increase you can code a simple test in Python.
Define a quadratic function and then compute the gradient a few times.
def gradient_loop(runs=3):
""" Repeatedly computes the gradient of a function
Computes the gradient given the starting points and then uses the result of the gradient to feed the next iteration, with new points.
Prints out the result of the function at each iteration
:param: runs: number of iterations to compute
""" # starting points
x = np.array([1, 2, 3])
# quadratic function, a parabola
y = x**2
for run in range(0, runs):
print("Iter " + str(run) + ": Y=" + str(y)) # compute first derivative
x = np.gradient(y, 1) # update the function output
y = x ** 2
gradient_loop()
In this case, the function gradient_loop takes a parabola y = x², and a handful of points represented by x. Then it calculates the gradient for the function at those points and carries that results as the set of points for the next iteration.
Since the gradient always wants to reach the summit of the mountain, you can see the value of the function increasing in each iteration.

This would be perfect if you were looking for the maximum value of a function, but in Gradient Descent you want to find the minimum, you want to reach the base of the mountain.
So, in Gradient Descent, you need to make the gradient go in the opposite direction [4].
Gradient Descent Algorithm
At a very high-level, or in pseudo-code, Gradient Descent follows these steps:
- Pick a random point w in the function, this is the starting point
- While the gradient hasn’t converged:
2a. Compute the negative gradient at w, the gradient going in the opposite direction.
2b. Update point w with it the result of 2a, and go back to step 1.
3. Success, you’ve found the minimum.

1. Pick a random point in the function
On the initial step you just need to pick a random point in the function, represented by the row vector w.
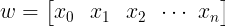
2. While the gradient hasn’t converged
This is the iterative part of the algorithm, and the idea is to keep going until you’ve reached the minimum.
But you won’t know when to stop. The whole reason why you’re running this algorithm is to find the minimum.
To mitigate this, you set a convergence threshold.
If, compared with the previous iteration, the new gradient of point w hasn’t changed more than the convergence threshold you’ve defined, the algorithm has converged. You declare you’ve found the minimum value of the function.
So, while the gradient hasn’t converged, on each iteration you will
- Compute the negative gradient at w.
- Update point w with it the result of 2a, and go back to step 1.
Mathematically speaking, on each iteration, you run an update rule, where you define the next point you’ll descent do, a point that’s further down the function.

That’s why it’s crucial that the function is convex. If the function is not convex, you might think you’ve found the absolute minimum, but you actually landed at a local minimum.

Looking at the update rule, there’s the current point w, the gradient, and then there’s the learning rate alpha.
What is this learning rate alpha?
The learning rate alpha is the size of the step Gradient Descent takes all the way until it reaches the global minimum, and it directly impacts the performance of the algorithm.
Learning rate is too big
When the learning rate is too big, you’re taking big steps. You may step over the minimum a few times, and then go back and forth several times. With big steps, Gradient Descent may never even reach the minimum and converge.
One way to spot that alpha is too big is when the gradient is not decreasing at every step.
Learning rate is too small
When the learning rate is too small, you’re taking tiny steps at a time. The algorithm will eventually converge, but it might take a long time to do so.

Gradient Descent’s Limitations
Gradient Descent is a powerful algorithm. But in a real-world scenarios with ever growing datasets, it has two major limitations:
- Calculating derivatives for the entire dataset is time consuming,
- Memory required is proportional to the size of the dataset.
Gradient Descent’s update rule is applied to all data points in the dataset, it all in one step. As the dataset increases this computation becomes much slower, so the time to convergence will increase.
These computations are typically done in memory so, the larger the dataset, the greater the memory requirements[5].
This is where Stochastic Gradient Descent comes in!
Stochastic Gradient Descent
With the limitations of Gradient Descent in mind, Stochastic Gradient Descent emerged as a way to tackle performance issues and speed up the convergence in large datasets.
Stochastic Gradient Descent is a probabilistic approximation of Gradient Descent. It is an approximation because, at each step, the algorithm calculates the gradient for one observation picked at random, instead of calculating the gradient for the entire dataset.

This represents a significant performance improvement, when the dataset contains millions of observations.
The only condition in Stochastic Gradient Descent is that expected value of the observation picked at random is a subgradient of the function at point w[4].
Compared to Gradient Descent, Stochastic Gradient Descent is much faster, and more suitable to large-scale datasets.
But since the gradient it’s not computed for the entire dataset, and only for one random point on each iteration, the updates have a higher variance. This makes the cost function fluctuate more on each iteration, when compared to Gradient Descent, making it harder for the algorithm to converge.
New variations of Stochastic Gradient Descent have been developed to tackle these problems. For example Mini-batch Stochastic Gradient Descent, addresses the variance problem by picking a sample of n observations from the dataset in each iteration instead of just one [5].
Let’s see Stochastic Gradient Descent in action!
Predicting the cooking time of your pizza
You and your close friends have distinct preferences when it comes to the perfect homemade pizza.
Recently, in one of your group chats, someone kicked-off the conversation about what makes the perfect pizza and suggested they’ve nailed their personal favorite recipe.
They can even time the cooking according to the different combination of ingredients, and get predictable results every time.
For a while, you’ve been trying to perfect your recipe as well. But, the idea that you could create your personal favorite pizza with a precise cooking time, was intriguing.
So, why not use your Data Science skills to tackle this?
First order of operations, start experimenting and taking notes! Even though you don’t know the right proportions yet, there are four things that make the perfect pizza:
- Oven temperature,
- Cheese,
- Sauce,
- Extra ingredients.

Looking back at your detailed culinary field notes, your dataset looks something like this:

You’re also assuming a linear relationship between the cooking time and the features that makes your perfect pizza. So, to predict the cooking time of your perfect homemade pizza you’ve decided to use a Linear Regression model and use Stochastic Gradient Descent to minimize the cost function, Ordinary Least Squares.
ScikitLearn has very thorough documentation on Stochastic Gradient Descent and the different functions available. There’s also plenty of room to tune the different parameters.
You’ll use your entire dataset to train the model, and then predict the cooking time for a pizza that has:
- Oven temperature: 510 F,
- 50g cheese,
- 35g sauce,
- 10g of your favorite ingredients.
Before the model is fit to the dataset, you need to scale your features, using a Standard Scaler. Since the goal is to take steps towards the minimum of the function, having all features in the same scale helps that process. It makes it so that each step has the same size across all features.
Using the pipeline, guarantees that all features are scaled before the model is used. Pipelines in Python are used to chain transformations to apply to an estimator, in this case the Stochastic Gradient Descent.
import time
import numpy as np
from sklearn.linear_model import SGDRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScalerdef stochastic_gradient_descent(feature_array, target_array, to_predict, learn_rate_type="invscaling"):
""" Computes Ordinary Least SquaresLinear Regression with Stochastic Gradient Descent as the optimization algorithm.
:param feature_array: array with all feature vectors used to train the model
:param target_array: array with all target vectors used to train the model
:param to_predict: feature vector that is not contained in the training set. Used to make a new prediction
:param learn_rate_type: algorithm used to set the learning rate at each iteration.
:return: Predicted cooking time for the vector to_predict and the R-squared of the model.
""" # Pipeline of transformations to apply to an estimator. First applies Standard Scaling to the feature array.
# Then, when the model is fitting the data it runs Stochastic Gradient Descent as the optimization algorithm.
# The estimator is always the last element.
start_time = time.time()
linear_regression_pipeline = make_pipeline(StandardScaler(), SGDRegressor(learning_rate=learn_rate_type))
linear_regression_pipeline.fit(feature_array, target_array)
stop_time = time.time()
print("Total runtime: %.6fs" % (stop_time - start_time))
print("Algorithm used to set the learning rate: " + learn_rate_type)
print("Model Coeffiecients: " + str(linear_regression_pipeline[1].coef_))
print("Number of iterations: " + str(linear_regression_pipeline[1].n_iter_)) # Make a prediction for a feature vector not in the training set
prediction = np.round(linear_regression_pipeline.predict(to_predict), 0)[0]
print("Predicted cooking time: " + str(prediction) + " minutes") r_squared = np.round(linear_regression_pipeline.score(feature_array, target_array).reshape(-1, 1)[0][0], 2)
print("R-squared: " + str(r_squared))feature_array = [[500, 80, 30, 10],
[550, 75, 25, 0],
[475, 90, 35, 20],
[450, 80, 20,25],
[465, 75, 30, 0],
[525, 65, 40, 15],
[400, 85, 33, 0],
[500, 60, 30, 30],
[435, 45, 25, 0]]target_array = [17, 11, 21, 23, 22, 15, 25, 18, 16]
to_predict = [[510, 50, 35, 10]]stochastic_gradient_descent(feature_array, target_array, to_predict)
Your pizza will take 13 minutes to cook, and it took the algorithm 249 iterations to find the minimum!

In this Python implementation of Stochastic Gradient Descent for regression, the default algorithm to pick the learning rate is inverse scaling.
But there are many ways to pick the learning rate, which directly affects how the algorithm performs.
How to pick the learning rate
You can use a different algorithm to pick the learning rate, depending on the problem and the dataset at hand.
The simplest algorithm is to pick a constant, a small enough number, say 10^-3. You start using it and gradually increase it or decrease it depending on how fast or slow gradient descent finds the minimum.
But, ideally you’d want to have an automated way to pick the learning rate. Instead of it being based on constants and tuning by trial and error.
You can use, for instance, an adaptive algorithm, which picks the learning rate based on the gradient from previous iterations. For example, Adam[6] Adadelta[7] use a decaying average of past gradients.
Re-running the code above, now with an adaptive learning rate just requires changing the learn_rate_type parameter.
stochastic_gradient_descent(feature_array, target_array, to_predict, learn_rate_type="adaptive")Your pizza still takes 13 minutes to cook, but it took only 98 iterations for Stochastic Gradient Descent to find the minimum!

The predicted cooking time is still the same, but there are several improvements:
- R-squared is higher, meaning the model is a better fit for this dataset.
- Total runtime is lower than with inverse scaling.
- The model converged much faster, requiring only 60% fewer iterations.
In this small dataset the difference in runtime and number of iterations is minimal, negligible really.
But you can imagine the impact of changing the learning rate algorithm in a dataset with thousands of features and millions of observations!
You just modeled the cooking time for your favorite pizza recipe with Stochastic Gradient Descent!
This was a simple example, but I hope you enjoyed it! Now you have a better understand about the power of Gradient Descent and how Stochastic Gradient Descent is a better solution for real-world large-scale problems.
Thanks for reading!
References
[1] Lemaréchal, C. (2012). Cauchy and the Gradient Method. Doc Math Extra: 251–254
[2] Larson, R. & Edwards B. (2006) Calculus: An Applied Approach (7th ed.) Houghton Mifflin
[3] The Gradient, Khan Academy
[4] Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge: Cambridge University Press.
[5] Ruder, S. (2017). An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747
[6] Diederik P. Kingma and Jimmy Ba (2017) Adam: A Method for Stochastic Optimization arXiv preprint arXiv:1412.6980
[7] Zeiler, Matthew D. (2012) ADADELTA: An Adaptive Learning Rate Method. arXiv preprint arXiv:1212.5701.
[8]Rie Johnson and Tong Zhang. 2013. Accelerating stochastic gradient descent using predictive variance reduction. In Proceedings of the 26th International Conference on Neural Information Processing Systems — Volume 1 (NIPS’13).
Images by author except where stated otherwise.

